一种简单有效的知识库搭建方法
AI私有化部署带来的挑战
- 有高额的初期投资,购买高性能服务器和显卡,个人部署使用的话,几万块是需要的。
- 技术门槛也不低,目前的终端软件还没有做到极其傻瓜化,需要敲命令,或者理解一些虚拟化或者容器化的计算机知识,对非专业的用户来说还是不方便的,尤其遇到需要升级或者出故障要排错,更是让人头疼。
私有知识库的意义
现在整个AI领域的进程还处于各大厂军备竞赛和跑马圈地的阶段,我们普通用户可以免费得到很多资源(比如各大厂免费的AI问答,各AI算力平台的免费Token),但跑马圈地之后呢?无一不是圈好栅栏开始收割的。尤其对于私人知识库,这么重要的私人资料被绑架在人家平台上,被强迫每年缴费,资料越攒越多,但平台限制取回资料,这种感觉相信大家都尝到过。上一个时代的笔记王者“印象笔记”就是这样一步一步堕落成连基本的"笔记"功能都做不好,还频繁弹广告,但你的笔记全在他上面,奈何?
所以,我们的理念是,越重要的东西就越是要把握在自己的手里,甭管这个大平台那个大公司,做出产品来都是需要消费者的,我们付钱消费,他们的产品只能是为我们助力的工具,而不能本末倒置。
所以说,
- 越专有越敏感的数据越是不能上云。
- 越是核心的数据越是要防备被平台绑架。
核心原理
站在普通用户的角度,我们只需要理解AI模型分为“嵌入模型”和“生成模型”
- 嵌入模型:把我们的本地文档转化成另一种计算机可以搜索的格式(“向量库”),我们输入关键词,他返回相关联的内容。
- 生成模型:我们提交问题和场景描述,他进行推理和整理成合乎逻辑的语言。
其中,部署和运行嵌入模型的资源消耗并不算大,但生成模型的资源消耗非常大,这也就是什么NVIDIA的显卡卖的那么贵,也只有头部的互联网大厂才有那么大的财力去搭建AI平台。
比如我们部署的通用的嵌入模型BAAI/bge-m3,在一台32G内存的Mac上测试依然运行十分缓慢,需要10秒钟才能处理一个word文档,这对于少量资料来说已经是够用了,但对于积攒了几千个word文档的知识库来说就太低效了。
而对于生成模型,比如 deepseek-r1:1.5b 或者 deepseek-r1:7b模型,这些小模型确实可以流畅运行,但无法带来很高的推理质量,因为参数太少,但部署了 deepseek-r1:14b或更大规模的模型后运行起来却慢如蜗牛,绝对无法成为生产力。
多种搭建方法
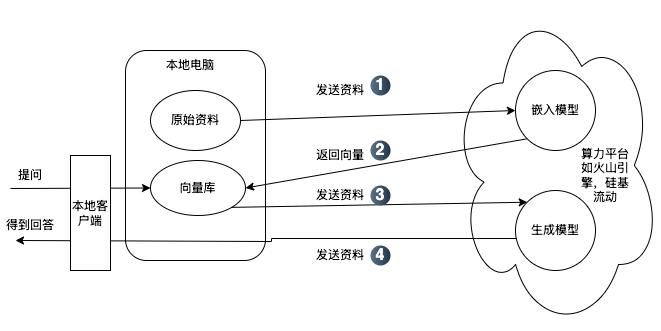
站在普通用户角度看,我们有两种私有化的场景和方法
-
如果数据量较大,且自己的PC性能也一般,数据敏感性也没有那么强,可以考虑本地用本地客户端+算力平台的方式解决。就是“原始资料”在本地,通过算力平台的API调用嵌入模型,将原始资料加工成“向量库”,然后我们想要对知识库发起问题的时候,本地客户端会先查询向量库得到相关的核心知识,然后再通过算力平台的API调用生成模型生成一个完整的答案。该方案的优点是”原始资料“和二次加工的资料(即”向量库“)完全在本地,虽然这些数据会过一道平台,数据的安全性保障就靠平台的自觉性了,但这也是无奈之举,至少保障了自己的数据不会被别人绑架,最多这个平台不行了以后换个平台用API,我们是有选择权的。[参考上图]
-
数据量不大,或者自己的PC性能很强,而数据的敏感性又很强,则考虑完全本地化部署模型。好处是数据彻底不出公网,私密性最强。跟上图中的区别就是嵌入模型和生成模型都在你本地。
最简单且有效的方法
目前市面上最匹配的两个免费客户端是Cherry Studio(国产的)和AnythingLLM(美国的),我们实践较多的是Cherry Studio,因为Cherry Studio的文档已经很丰富了,而且图文并茂,所以,上手门槛比较低,这里就不赘述了,而是列一下关键步骤和官网链接。
-
要去算力平台注册账号,并获得API token。这里推荐使用硅基流动,因为他的嵌入模型
BAAI/bge-m3是完全免费的。他的生成模型中质量好的模型都是要收费的,但是有一定的免费额度赠送,其他算力平台的收费模式也是类似,毕竟大模型的硬件成本很高。 -
在Cherry Studio上添加算力平台的方法看 这里 。
-
然后在Cherry Studio上添加嵌入模型,添加数据库和提问,看 这里。
-
这里 是本地数据的保存位置和做数据备份的方法。
想要获得高价值的参考信息,原始资料的高价值是关键,我们不可能在一堆垃圾中挖掘到宝藏。我们做了一个实测,我们把“齐俊杰粉丝群和读书圈”历年的所有理财资料Word和PDF文件都灌入到Cherry Studio中,大概5个G,通过BAAI/bge-m3向量化后的数据集是850M,使用deepseek-r1-250125生成模型提问,分别问了2个问题
- 医药生物行业的投资逻辑
- 光伏行业的投资逻辑


针对这个答案我们还是非常满意的,而且还有信息的出处作为注脚,这样很方便我们去原文求证。有了这个办法,做投研的效率真的是提高了不少,再多资料也能够消化得了。
几点提醒
- 目前市面上的模型非常多,大家要根据自己的需求仔细斟酌,选错了模型就会得到不理想的效果。关于如何选择模型,我们会用另外的篇章来解释。暂时只需要简单区分“通用型“和”推理型“,如果需要做严格的逻辑推理,对准确性要求比较高,那么就要选择类似
deepseek-r1这样的推理型生成模型,如果只是要求帮助写文章,那么deepseek-v3这种通用型模型就可以了。 - 因为,推理型的模型需要较长实践的思考过程,所以为了得到一个准确度较高的答案,需要耐心等待,不要以为程序卡死了。
- 还有其他问题或者需求,可以公众号联系”智慧谷星球“。