产品介绍
智能体助手(Knowlify AI)是“第二大脑计划”的一部分,该工具的目标是将互联网上主流格式的资料转化成AI可以理解的语料库,然后借助于AI的能力快速提取关键信息,并跟AI一起结伴思考和决策,使得我们可以快速对某一个领域的知识有深刻的洞见。最适合的场景是“行业调研”和“投资决策”。
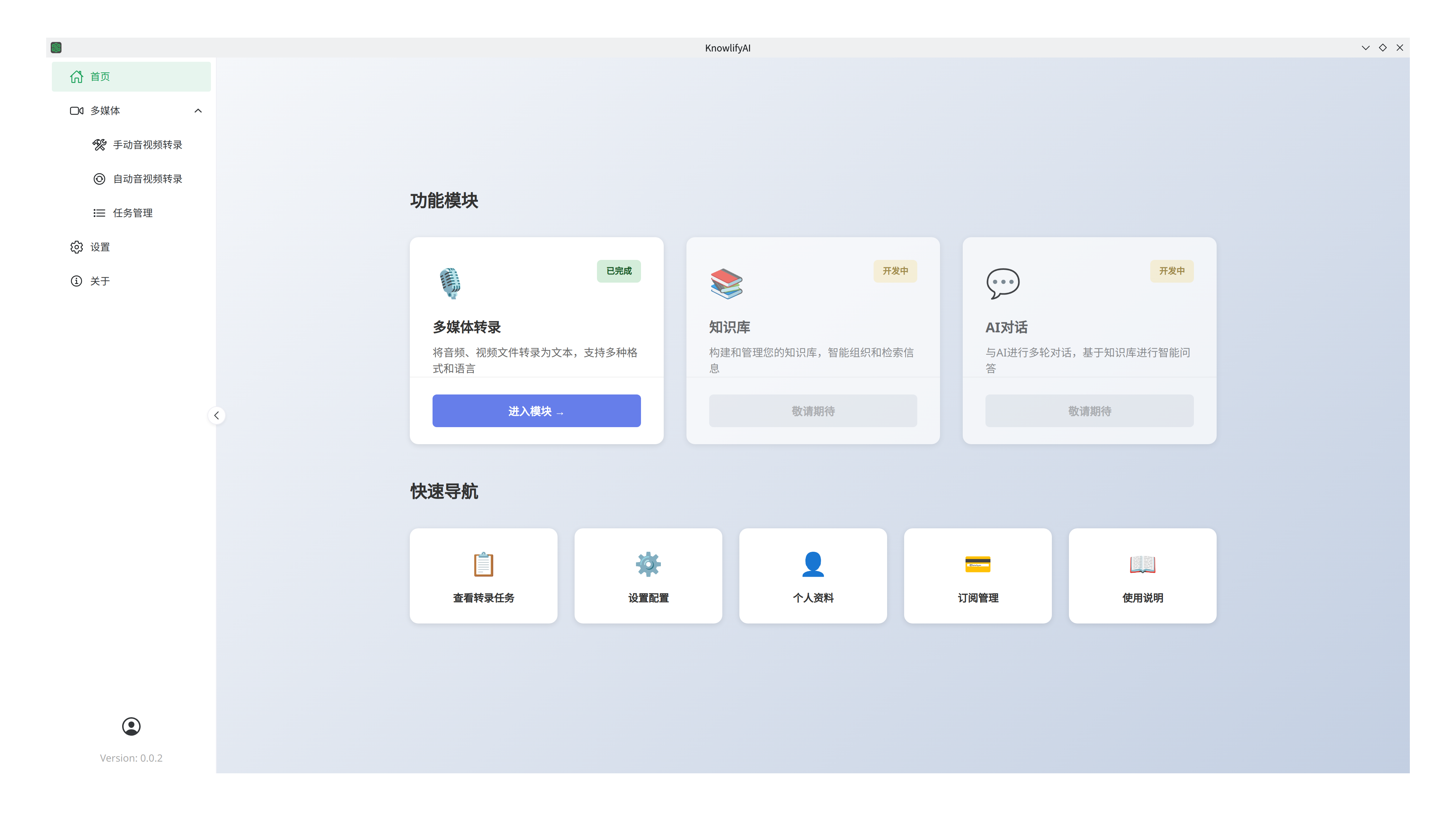
版本选择和下载
本软件支持 Windows,Linux,macOS系统,并区分CPU版本和GPU版本(仅NVIDIA显卡)。
- 对于Windows系统,目前不支持ARM的CPU,仅支持x86_64的CPU。
- 如果有NVIDIA显卡,则选择 KnowlifyAI-Windows-x86_64-cuda.7z,内含CUDA支持。
- 其他情况(其他品牌显卡 或者 没有独立显卡)均选择KnowlifyAI-Windows-x86_64-cpu.7z。
- 对于macOS系统,Apple Silicon CPU(即arm64架构)则选择KnowlifyAI-macOS-arm64-mps.zip,其他CPU则选择KnowlifyAI-macOS-x86_64-mps.zip。另外,在macOS上运行软件可能会遇到的问题,请参考这里解决。
- 对于Linux系统,目前不支持ARM的CPU,仅支持x86_64的CPU。
- 如果有NVIDIA显卡,则选择 KnowlifyAI-linux-x86_64-cuda.7z,内含CUDA支持。
- 其他情况(其他品牌显卡 或者 没有独立显卡)均选择KnowlifyAI-linux-x86_64-cpu.7z。
- 下载地址点击 这里,因软件包非常大,在这里提供网盘备用下载,下载后请使用 7zip 解压缩,解压后无需安装,直接运行。
硬件要求
该软件会在本地计算机运行语音识别模型,模型需要使用3GB内存。
所以,对计算机配置的最低要求是
- CPU:4核以上;
- 内存:8G以上;
在过往的测试表现中,测试机 CPU AMD Ryzen 7 PRO 5850U (16 Core) @ 1.90 GHz + 内存 48G + 集成显卡(1G显存) 的电脑上,
- 6分钟的mp3, 3MB,处理时间在48秒;
- 1小时53分钟的mp3, 88MB,处理时间在14分钟;
在测试机 Intel(R) Xeon(R) E3-1270 V2 (8) @ 3.90 GHz + 内存 16 GB + NVIDIA RTX A2000(8G显存)的服务器上,
- 6分钟的mp3, 3MB,处理时间在5秒;
- 1小时53分钟的mp3, 88MB,处理时间在1分钟;
功能说明
多媒体转录
功能解释
多媒体转录,即音视频转文本,使用该功能可以让你从任意音频和视频文件中识别出文本,使得可以做文字搜索,或者直接通过AI建成智能体,从而快速提升从音频和视频中获取知识的效率。
应对场景
从B站或者油管上看到非常好的视频,但是非常长,或者博主的讲解速度非常慢,很难有耐心或足够的时间整个看完。或者买了网盘上的一大堆音视频的资料包,想要快速从中寻找到自己想要的内容,但是无从下手。
软件特色
- 支持大批量转录。目前百度简单听记 和 阿里听悟 之类的产品都有限制,前者不能批量,后者最多批量50个,且不支持批量下载转录后的文件,针对每个音视频还有长度限制。
- 支持对接AI模型处理转录的文字,修正错误和优化格式。可以对接大模型平台(如硅基流动,或者本地ollama)中的任何模型。
- 支持监控指定目录中的新文件,发现新文件就自动转录。
效果示范
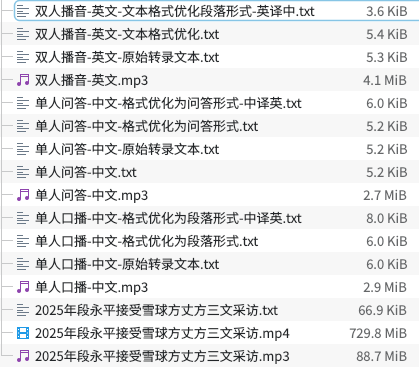
请移步这里 查看。
使用方法
本软件支持批量转录
- 你可以选择多个文件后批量提交,这些文件会被依次转录;
- 你也可以选择某个文件夹提交,软件会对该文件夹里的所有文件依次转录;
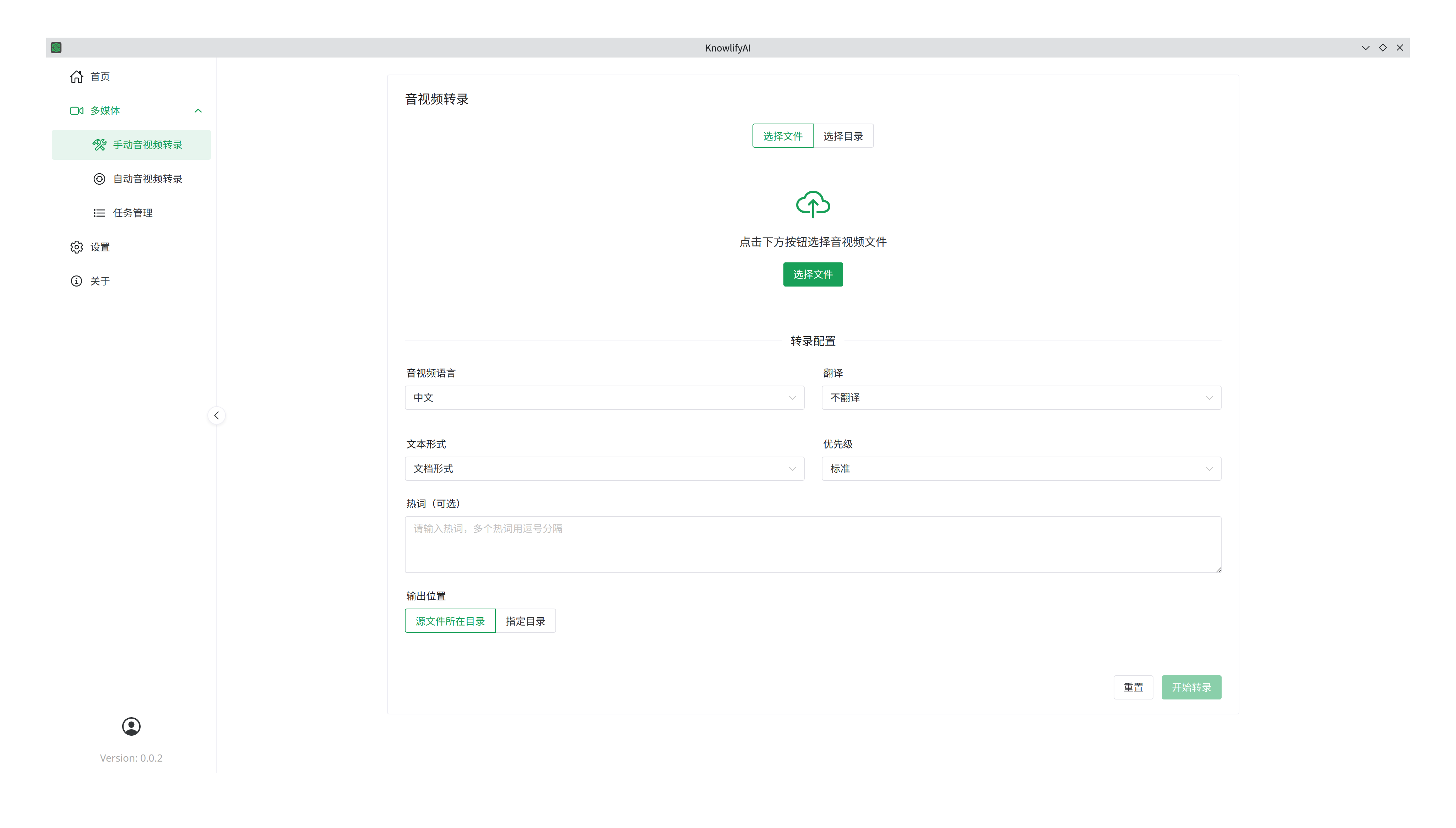
手动转录
可选参数有
- 音视频语言:目前仅支持英文和中文,可以是纯英文或中文,也可以是混合中英文;
- 翻译:将转录完后的内容翻译成你要的语言,目前也仅支持中文和英文;
- 文本形式(效果可以参考前面章节“效果示范”):
- 文档形式:对转录出来的文字不进行格式处理,仅进行错误修正(依赖于大语言模型);
- 问答形式:如果音视频内容是自问自答的Q&A或者两人的一问一答形式,选择此项后就会让输出的文字形式变成一问一答(依赖于大语言模型);
- 段落形式:适合单人或者多人演讲场合,选择此项后就会让输出的文字切割成自然段落,每个段落是一个独立的意思(依赖于大语言模型);
- 原始形式:对转录出来的文字不进行任何处理(无需大语言模型);
- 优先级:你可以批量提交很多转录任务,但可以给他们设定不同的优先级,优先级高的将会被优先转录;
- 热词:当视音频里有些发音非常模糊或者他们是多音字,这些都会导致识别不准确,但如果你在这里提供这些词,那么在最终的识别结果里,这些词的识别准确性将得到很大的提升;
- 输出位置:
- 源文件所在目录:如果你的音频文件在
D:\folder-1\file-1.mp3,那么转录的结果将保存在D:\folder-1\file-1.txt。 如果你有2个文件需要转录,他们分别在D:\folder-1\file-1.mp3和D:\folder2\file-2.mp3,那么他们的转录结果也将分别保存为D:\folder-1\file-1.txt和D:\folder2\file-2.txt; - 指定目录:转录的结果将全都被存放在这个指定的目录里;
- 源文件所在目录:如果你的音频文件在
操作步骤
- 选中标签,“选择文件”还是“选择目录”;
- 选择参数(见上面的解释);
- 右下角“开始转录”提交任务;
自动转录
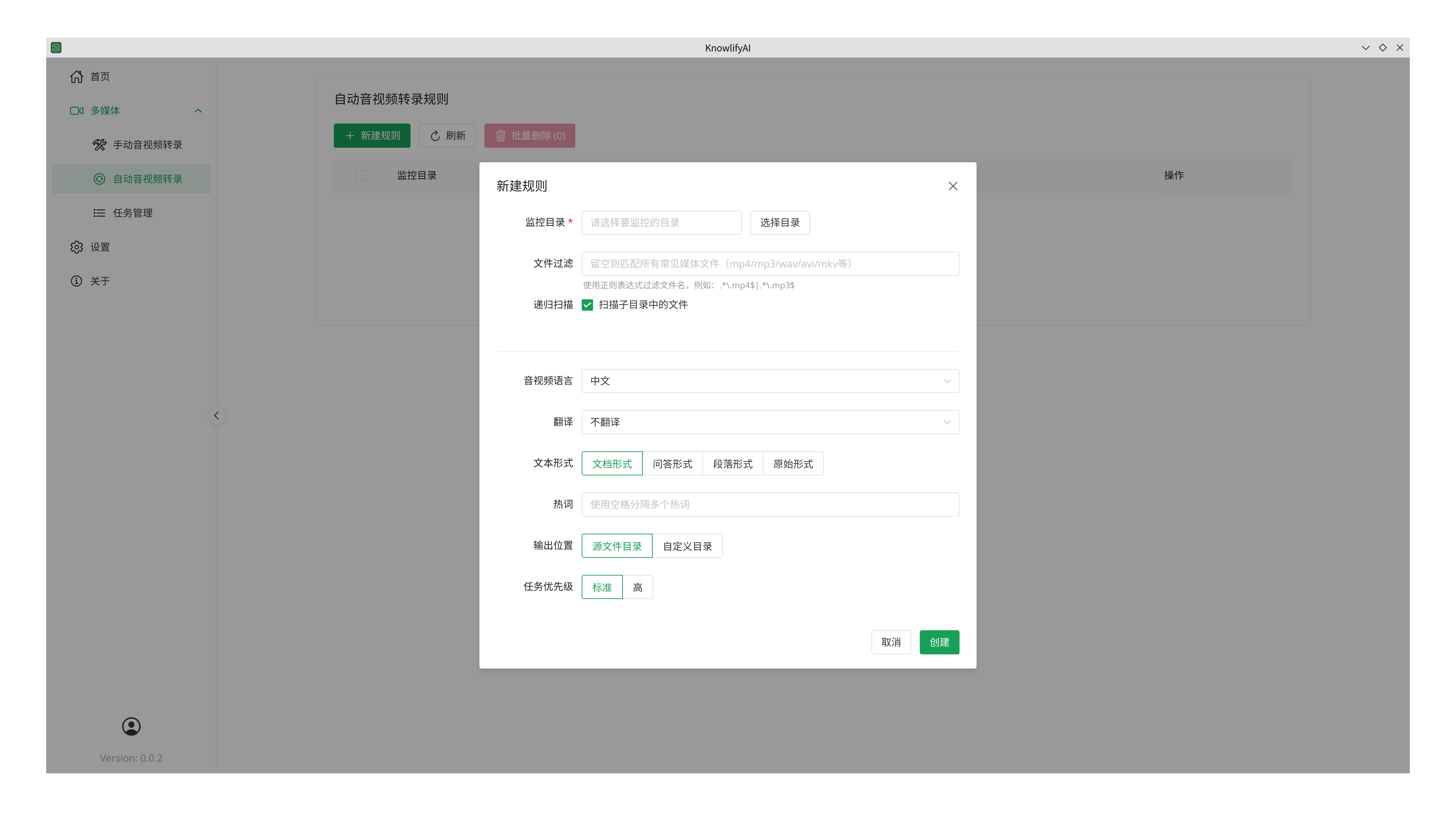
参数跟“手动”部分大部分一样,除了
- 监控目录,即只要该目录路出现新文件就会按照这里设置的参数进行转录。
- 文件过滤,如果不希望所有的新文件都转录,那么可以设定这里的规则,只转录符合规则的文件。你可以让豆包或者Deepseek帮你写正则表达式规则,然后用这个工具测试正确性。
- 递归扫描,是不是要扫描各级子目录,如果不选中,则只扫描一级目录,即不包括子目录和孙目录。
任务管理
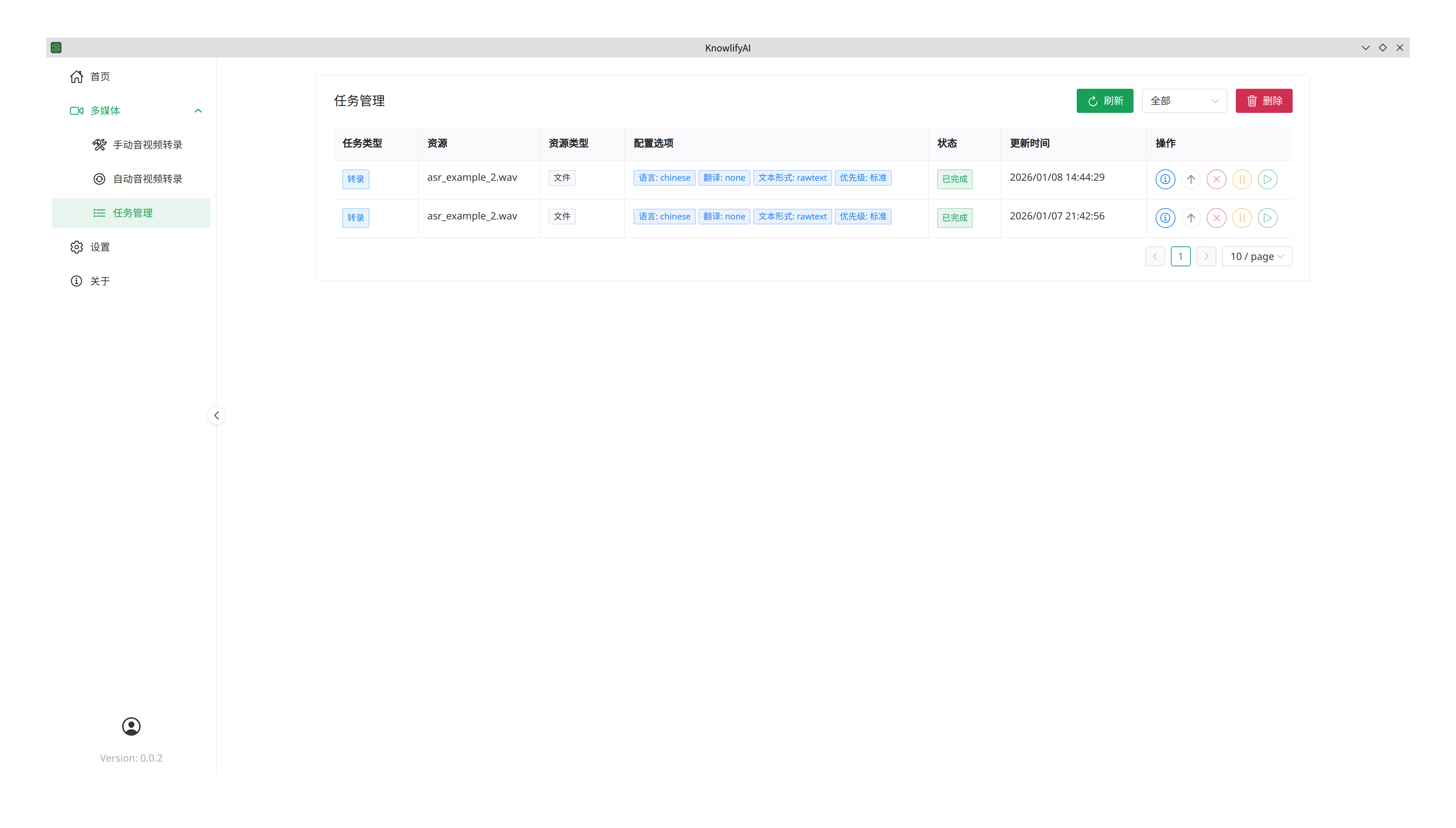
对每个任务,在“操作”列里的按钮分别是:详情,取消,暂停,恢复。
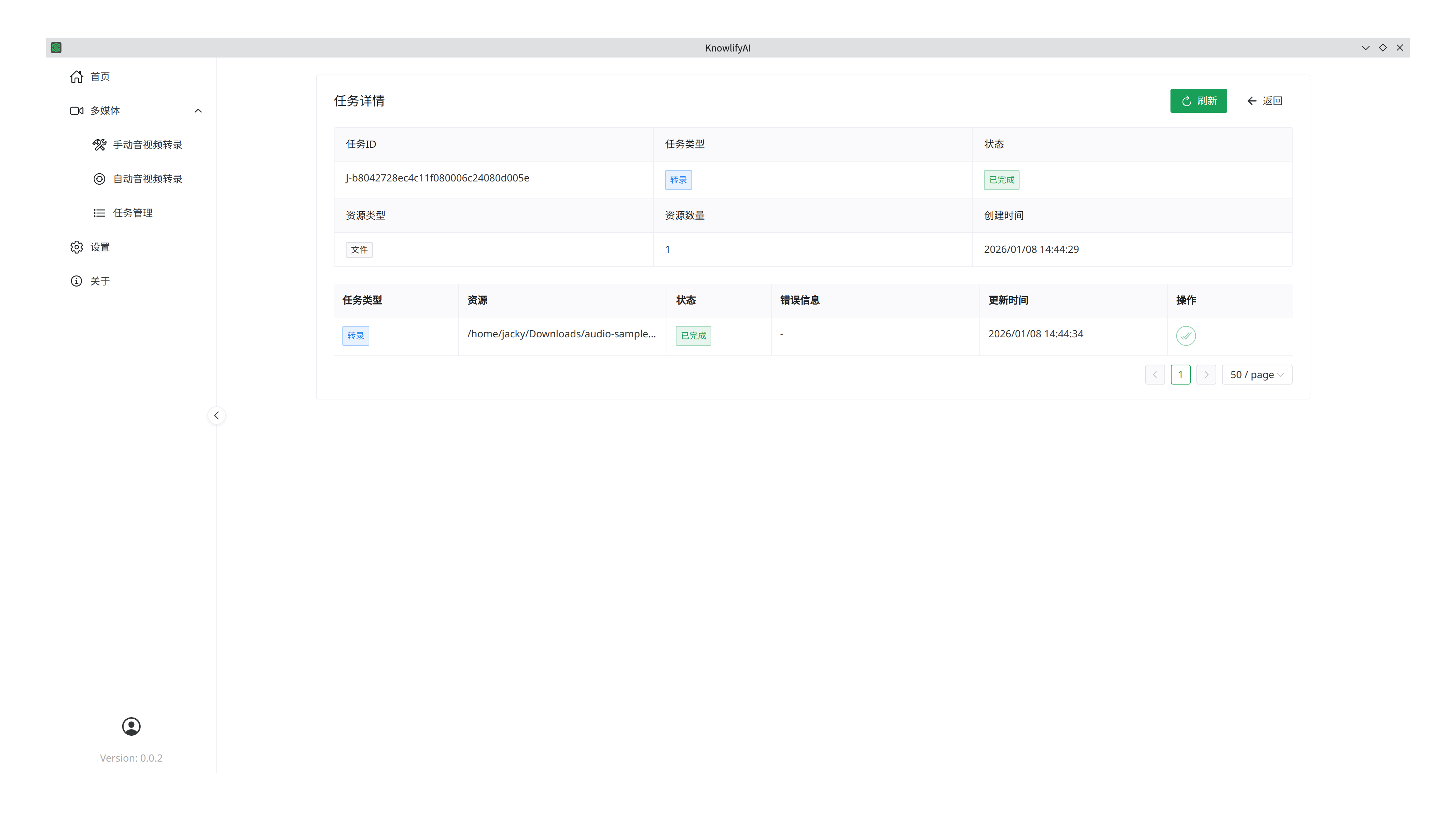
点击某个任务的详情后,将看到每个文件的转录进展和错误信息
设置
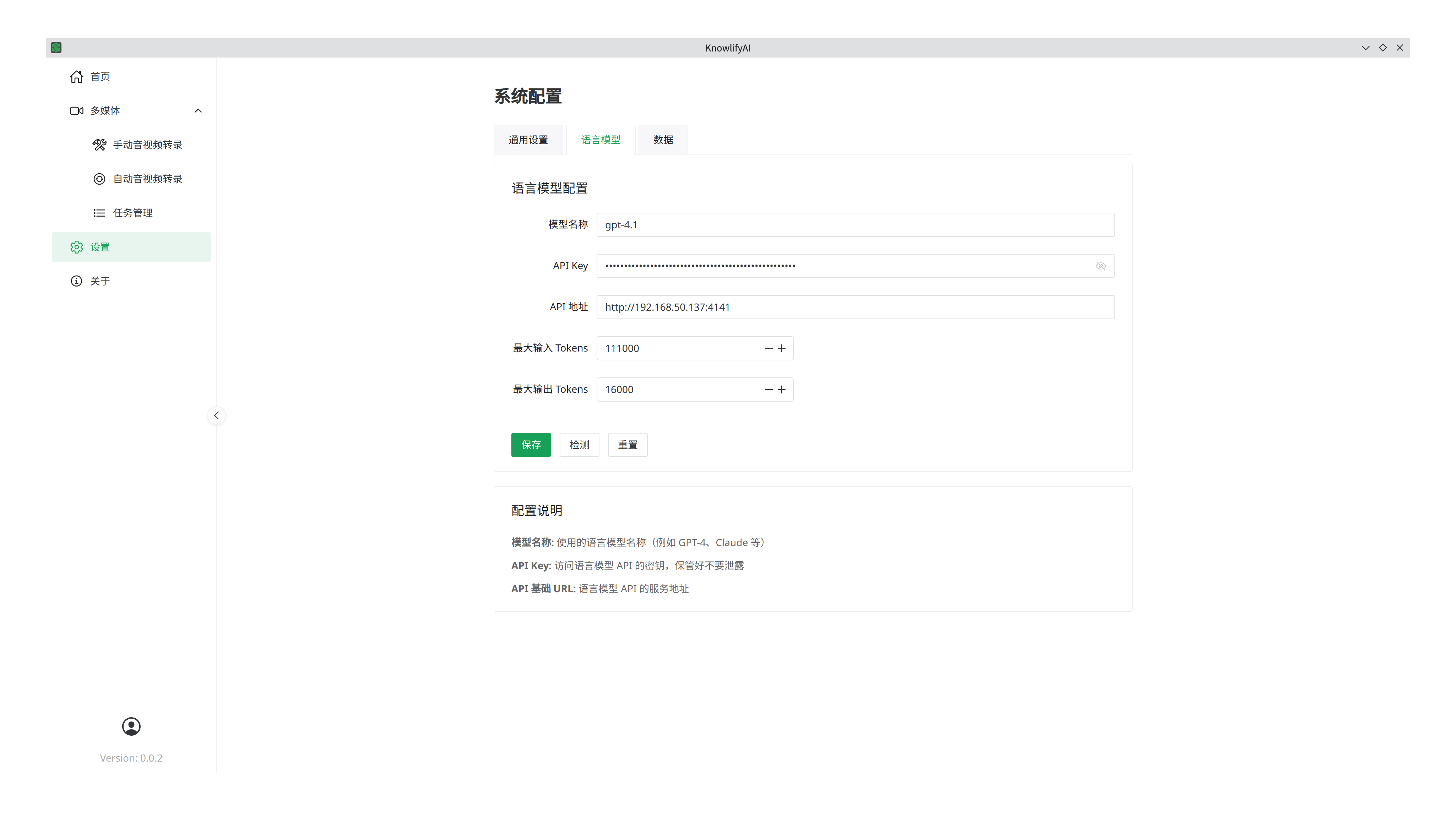
大模型设置
前面提到过有些功能是需要依赖于“大语言模型(简称LLM)”的,这里就是配置LLM的位置,我们以硅基流动的服务为例,先在他网站上注册并充值,然后点击API密钥,将密钥复制过来填入到“API Key”里面,“API 地址”填写为 “https://api.siliconflow.cn” ,“模型名称”则是从硅基流动的模型广场里找到的模型的名称,比如 “ deepseek-ai/DeepSeek-V3.2 ” (注意硅基流动网站上的模型名字会不定时更新,请以官网上的模型名字为准),点击“保存”后就可以在转录的时候自动发挥作用了(保存后点击“检测”可以检测模型是否可用)。如果没有设置LLM参数,那么软件执行的时候将会自动跳过需要LLM的步骤。
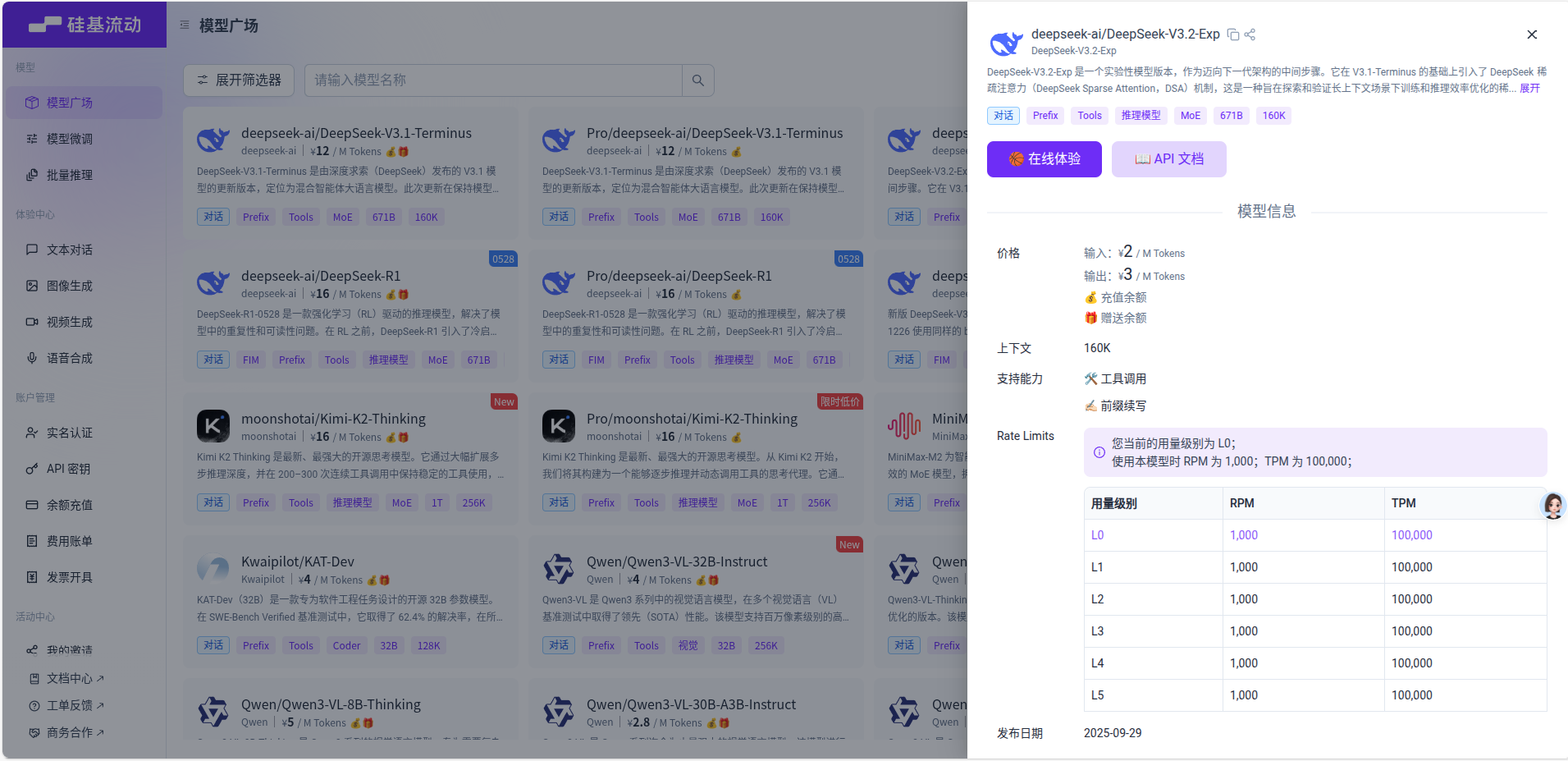
大模型供应商
目前支持的大模型供应商有
| 供应商 | 是否支持 |
|---|---|
| OpenAI | ✅ |
| Gemini | ✅ |
| Anthropic | ✅ |
| xAI | ✅ |
| SiliconFlow | ✅ |
| Moonshot | ✅ |
| DeepSeek | ✅ |
| Ollama | ✅ |
| 其他兼容OpenAI接口风格的供应商 | ✅ |
常用大模型的参数
| 参数 | DeepSeek-V3.2-Exp | GPT-5.1 | GPT-4.1 | Gemini-2.5-Pro | Claude-Sonnet-4.5 |
|---|---|---|---|---|---|
| 上下文窗口大小(tokens) | 160k | 400k | 1M | 1M | 200k(实验性支持1M) |
| 最大输出量(tokens) | DEFAULT: 32K ; MAXIMUM: 64K | 128k | 32k | 64k | 64k |
| 输入价格(Per 1M tokens) | ¥2.0 ($ 0.28) | $1.25 | $2.0 | $1.25, prompts <= 200k tokens ; $2.50, prompts > 200k tokens | $3.0, prompts <= 200k tokens ; $6.0, prompts > 200k tokens |
| 输出价格(Per 1M tokens) | ¥3.0 ($ 0.42) | $10.0 | $8.0 | $10.00, prompts <= 200k tokens ; $15.00, prompts > 200k | $15.0, prompts <= 200k tokens ; $22.50, prompts > 200k tokens |
重点参数解释
- 上下文窗口,也即最大输入量,关系到一次性调用模型的文本的长度的限制。比如,一个超长的音频转录出来有几万字,那么上面的模型都可以一次性接收。但如果是几百万字的文本,就要选择更大窗口的模型了,比如
1M窗口的模型。如果大模型的窗口小于我们的文本,那么就会失败,使得转录的结果仅保持原始形式的文本。 - 输入和输出价格,音视频转录后文本的处理对推理能力不是刚需,如果考虑到超长的文本和大量的转录需求,优先考虑成本低的模型,比如
DeepSeek-V3.2-Exp。
订阅
订阅的费用仅是本软件的使用费,不包括用户对大模型平台的使用费,用户可以在本软件中对接任何大模型平台的服务,在他们的平台中单独计费。
注意事项
- 当首次对音视频文件进行转录时,本软件会在后台下载AI模型,模型大小为几个GB,下载时间根据用户的网速不同而定,模型下载和载入完毕后才开始转录,所以首个音视频的转录等待时间会比较长,后续的转录就会很快。
- 其他问题请参阅 Q & A